Generatorul de analizoare lexicale FLEX
Principiul de functionare a programului FLEX
FLEX (Fast LEXical Analyzer Generator) este un generator
de analizoare lexicale si constituie unul dintre utilitarele standard ale sistemelor
de operare Unix. Se mentioneaza ca prezentul document se bazeaza pe versiunea
2.5.4 a programului FLEX.
Programul FLEX primeste la intrare un fisier continand
o specificatie a atomilor pe care urmeaza sa-i recunoasca analizorul generat,
precum si a actiunilor semantice de executat. Pe baza acestei specificatii
se genereaza un program C ce contine tabelele de analiza, impreuna cu functia
de analiza, numita yylex( ). In continuare se compileaza programul obtinut,
rezultand astfel analizorul lexical executabil.
Fisierul ce contine specificatia este un fisier text care poate avea orice nume acceptat de sistemul de operare. Din considerente istorice (care tin de versiunile pentru DOS ale programului LEX), se recomanda ca fisierul de specificatie sa aiba extensia .lxi.
Programul C rezultat este memorat intr-un fisier denumit implicit lex.yy.c (utilizatorul poate solicita explicit un alt nume). Efectuarea analizei lexicale asupra unui text sursa folosind analizorul generat de FLEX este ilustrata in figura de mai jos.
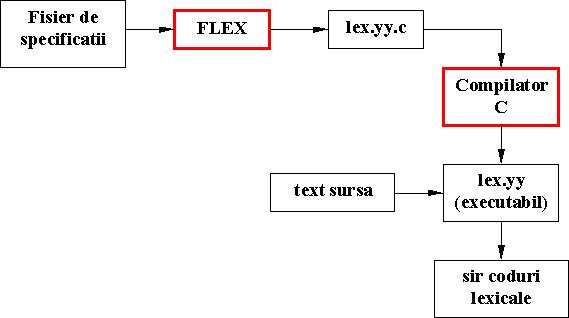
Lansarea in executie a programului FLEX
Lansarea in executie a programului FLEX se realizeaza cu comanda
In cazul in care nume_fisier_specificatii nu este precizat,
FLEX va astepta introducerea specificatiilor de la stdin.
Cateva dintre optiunile liniei de comanda mai des utilizate
sunt:
Structura programului de specificatie
Programul de specificatie contine in principiu expresiile
regulate ce descriu atomii limbajului sursa, precum si actiunile pe care
analizorul trebuie sa le execute la recunoasterea fiecarui atom.
Structura unui program de specificatie este urmatoarea:
Este utilizata in principal pentru a asocia nume expresiilor regulate, in scopul obtinerii unei specificatii mai simple si mai clare.sectiune_definitii
%%
sectiune_reguli
%%
cod utilizatorSectiunea de definitii
![]() Directivele
%option permit utilizatorului sa precizeze
unele optiuni legate de analizorul generat. Cateva asemenea optiuni sunt:
Directivele
%option permit utilizatorului sa precizeze
unele optiuni legate de analizorul generat. Cateva asemenea optiuni sunt:
%option main -- are ca efect generarea unei functii main() care nu face altceva decat sa apeleze functia de analiza yylex();%option caseless -- are acelasi efect ca si optiunea -i din linia de comanda;
%option debug -- are acelasi efect ca si optiunea -d din linia de comanda;
%option yylineno -- analizorul rezultat va contine cod care actualizeaza variabila globala yylineno cu valoarea curenta a numarului liniei sursa;
%option noyywrap -- aceasta optiune este foarte utila daca se doreste ca la o rulare a analizorului sa se parcurga un singur fisier sursa, asa cum de fapt trebuie sa se intample de cele mai multe ori.
Daca aceasta optiune lipseste, analizorul generat incearca sa prelucreze in lant mai multe fisiere sursa. Trecerea de la un fisier la altul se realizeaza prin apelul de catre analizor a unei functii numite yywrap(), la intalnirea marcajului EOF al fiecarui fisier sursa. Cum functia yywrap() nu exista in mod implicit, ea ar trebui definita de catre utilizator. Rolul acestei functii este sa deschida urmatorul fisier in variabila globala FILE *yyin si sa returneze 0, respectiv sa returneze o valoare nenula daca nu mai exista un fisier urmator.
![]() Secventele C definite de utilizator
in sectiunea de definitii
Secventele C definite de utilizator
in sectiunea de definitii
Utilizatorul are posibilitatea de a plasa in sectiunea de definitii secvente proprii de cod C. O modalitate de a introduce aceste secvente C este ca ele sa fie incluse intre perechile de caractere %{ si respectiv %}. Perechile %{ si %} trebuie sa apara pe linii separate si neindentate.
Codul cuprins intre aceste perechi (exclusiv perechile) va fi copiat ad-literam in analizorul generat, in spatiul de vizibilitate din afara functiei yylex(). Cu alte cuvinte, codul utilizator plasat in sectiunea de definitii va fi considerat ca spatiu de declaratii globale in raport cu functia yylex().
Scopul principal al acestei sectiuni este acela de a asocia actiuni semantice cu expresiile regulate. In plus, ea mai poate contine cod C definit de utilizator.
Daca actiunea este redata prin instructiunea vida, la recunoasterea sirului descris de sablonul in cauza, analizorul nu va executa nimic (de fapt, va trece pur si simplu la delimitarea urmatorului atom). In consecinta, atomii ale caror reguli au actiune vida sunt neglijati (filtrati sau eliminati). Comentariile si spatiile albe sunt exemple de siruri care se preteaza la un asemenea tratament.
Daca o actiune se termina cu instructiunea return,
aceasta va insemna iesirea din functia yylex(), altfel aceasta functie trece
automat la cautarea urmatoarelor potriviri. In concluzie, daca dorim ca
analizorul lexical sa prelucreze cate un singur atom la fiecare apel, va trebui
sa prevedem instructiuni return la toate actiunile care corespund unor
atomi valizi (nu comentarii sau spatii albe). Acest mod de lucru este potrivit
pentru compilatoarele care lucreaza intr-o singura trecere. Pentru
compilatoarele care lucreaza in mai multe treceri, analiza lexicala fiind o faza
distincta, actiunile se vor termina prin instructiuni de scriere (de exemplu
directiva ECHO) a codurilor lexicale intr-un fisier
de iesire (care ar putea fi yyout).
![]() Expresii
regulate
Expresii
regulate
In continuare, pe baza unor exemple se va descrie sintaxa
admisa de FLEX pentru expresiile regulate:
| x |
caracterul x |
| . |
orice caracter, mai putin marcajul de sfarsit de linie (\n) |
| \x |
daca x este unul dintre caracterele a, b, f, n, r, t sau v, atunci se aplica interpretarea ANSI-C (bell, backspace, form feed, new line, return, horiz tab si vertical tab); in caz contrar se interpreteaza drept caracterul x (aceasta forma se utilizeaza daca x coincide cu unul dintre operatorii expresiilor regulate, pentru a nu fi confundat cu acestia) |
| \123 |
caracterul al carui cod in octal este 123 |
| \x2a |
caracterul al carui cod in hexa este 2a |
| [xyz] |
oricare dintre caracterele x, y sau z; o asemenea constructie se numeste clasa de caractere |
| [j-q] |
oricare dintre caracterele din intervalul j - q (j, k, l, m, n, o, p, q) |
| [a-zA-Z] |
orice litera |
| [^A-Z] |
orice caracter, cu exceptia literelor mari; se precizeaza ca semnul de excludere ^ are acest rol doar daca apare imediat dupa paranteza dreapta deschisa; |
| [^A-Z\n] |
orice caracter, cu exceptia literelor mari si a marcajului de sfarsit de linie |
| "[abc]\"xyz" |
sirul de caractere [abc]"xyz (fiind incluse intre ghilimele, parantezele drepte nu mai au rol de a defini o clasa de caractere) |
| r* |
zero sau mai multe aparitii succesive ale expresiei regulate r |
| r+ |
una sau mai multe aparitii succesive ale expresiei regulate r |
| r? |
una sau zero aparitii ale expresiei regulate r |
| r{2,5} |
2, 3, 4 sau 5 aparitii succesive ale expresiei regulate r |
| r{2,} |
2 sau mai multe aparitii succesive ale expresiei regulate r |
| r{4} |
exact 4 aparitii succesive ale expresiei regulate r |
| {alfa} |
se expandeaza la expresia regulata careia i s-a asociat numele alfa in sectiunea de definitii |
| (r) |
expresia regulata r, evaluarea ei avand prioritate fata de operatiile din afara prantezelor |
| rs |
concatenarea expresiilor regulate r si s |
| r|s |
una dintre expresiile regulate r sau s |
| r/s |
expresia regulata r, dar cu conditia ca ea sa fie urmata de expresia s (pozitia curenta in fisierul sursa ramane inaintea expresiei s) |
| ^r |
expresia regulata r, cu conditia ca ea sa apara la inceputul liniei sursa |
| r$ |
ca mai sus, dar expresia sa apara la sfarsitul liniei sursa (echivalent cu r / \n) |
| <<EOF>> |
marcajul de sfarsit de fisier sursa |
| <s>r |
expresia regulata r, dar numai in conditia de start s |
In ceea ce priveste actiunile si secventele de cod inserate
in sectiunea de reguli, ele pot contine referiri la variabile globale,
respectiv apeluri la unele macro-uri si functii utilitare predefinite.
Cateva dintre variabilele utile sunt:
Obs: daca n este 0, inseamna ca intreg atomul este restituit sirului de intrare; acest lucru ar duce la intrarea intr-o bucla infinita a analizorului, deoarece in pasul urmator acealsi atom va fi recunoscut, ajungandu-se la acelasi apel al lui yyless. Argumentul 0 poat fi totusi utilizat cu succes, daca inaintea apelului la yyless, se modifica starea de start (vezi directiva BEGIN);
Obs: daca se doreste plasarea in sirul de intrare a unui string de caractere, se va apela unput pentru fiecare caracter, incepand de la ultimul pana la primul. Se precizeaza ca argumentul c NU POATE FI CARACTERUL EOF ! Inaintea folosirii functiei unput trebuie facuta o copie a zonei yytext, deoarece continutul ei este alterat incepand cu caracterul cel mai din dreapta.
![]() Secventele C definite de utilizator
in sectiunea de reguli
Secventele C definite de utilizator
in sectiunea de reguli
In sectiunea de reguli, la fel ca in cea de definitii, utilizatorul poate sa plaseze secvente de cod C (altele decat cele care reprezinta actiuni atasate expresiilor regulate). Sintaxa utilizata pentru asemenea secvente este aceeasi ca in cazul sectiunii de definitii.
Codul utilizator din sectiunea de reguli va fi copiat in analizorul generat, in INTERIORUL functiei yylex(). Ca urmare, se recomanda ca secventele C utilizator sa fie plasate inainte de prima regula. De obicei asemenea secvente vor contine declaratii locale in raport cu functia yylex(), respectiv operatii (de exemplu initializari ) care se vor executa la fiecare apel al lui yylex().
Acesta sectiune a fisierului de specificatii este optionala (daca lipseste, atunci si separatorul %% care urmeaza dupa sectiunea de reguli poate lipsi). Daca este prezenta, atunci continutul ei, care consta in cod C utilizator, este copiat fara modificari la sfarsitul fisierului lex.yy.c.
In mod normal, in sectiunea de cod utilizator pot sa apara:
Modul de functionare a analizorului generat de FLEX
(functia yylex)
Modul de functionare al analizorului yylex() este guvernat de urmatoarele principii:
Cand analizorul intalneste marcajul EOF, el verifica rezultatul functiei yywrap(). Rezultat fals (zero) inseamna ca analiza trebuie sa continue cu noul fisier desemnat de yyin. Un rezultat nenul al functiei yywrap() determina sfarsitul analizei si returnarea valorii 0 spre apelantul lui yylex().
Absenta functiei yywrap() poate fi suplinita de optiunea %option noyywrap sau prin linkeditare cu optiunea -lfl (ambele variante presupun return 1).
FLEX poate genera analizoare lexicale capabile sa analizeze un fisier sursa in care apar secvente de cod scrise in limbaje diferite (carora le corespund seturi de expresii regulate diferite). Pentru aceasta exista un mecanism care permite activarea dinamica a unui anumit set de reguli, in functie de o asa-numita stare de start.
Starile de start trebuie mai intai declarate in sectiunea de definitii. Declararea se face conform sintaxei:
%s lista_nume_stari_de start_inclusive
sau
%x lista_nume_stari_de_start_exclusive
unde numele din liste sunt separate prin spatii.
In continuare, numele starilor de start vor servi drept etichete atasate anumitor reguli din sectiunea de reguli, precum si ca argumente ale directivelor BEGIN.
In urma executiei unei directive BEGIN, analizorul trece in starea de start ce apare ca argument al directivei. Din acest moment analizorul va folosi regulile ce corespund conditiei respective:
Se precizeaza ca o aceeasi regula poate fi etichetata cu una sau mai multe stari de start. Etichetarea se face conform sintaxei:
<lista_nume_stari_de_start>regula
unde numele din lista sunt separate prin virgule.
Exemplu
In cele ce urmeaza este prezentat un exemplu de fisier de specificatii pentru un subset foarte restrans al limbajului Pascal, care ilustreaza principalele aspecte enuntate in paragrafele de mai sus. Presupunand ca numele acestui fisier este sspas.lxi, comenzile necesare pentru a genera analizorul lexical corespunzator si pentru a-l lansa in executie sunt:
$ flex sspas.lxi
$ gcc lex.yy.c -o alex
$ ./alex nume_fisier_sursa
In ultima comanda nume_fisier_sursa poate
lipsi, caz in care se va astepta introducerea textului sursa de la stdin
(tastatura).
Observatie: daca se alege aceasta
ultima varianta,
marcajul de sfarsit de fisier este combinatia Ctrl-D.
La executia analizorului lexical se va putea observa ca prezenta in fisierul sursa a secventelor {+d} si {-d} au ca efect activarea, respectiv dezactivarea in mod dinamic a regimului de lucru "debug".
/* <math.h> este necesara pentru functia de conversie atof() */ #include <math.h> %} /* noyywrap precizeaza faptul ca analiza
lexicala se face dintr-un singur
fisier sursa */
/* analizor lexical case-insensitive */
/* analizor lexical cu cod debug inclus */
DIGIT [0-9]
%%
{DIGIT}+ {
}
}
} /* ATENTIE - deoarece definitia ID este acoperitoare in raport cu definitiile cuvintelor cheie, regulile atasate acestora trebuie plasate inaintea regulii pentru ID; in caz contrar si cuvintele cheie vor fi interpretate ca identificatori */ "+"|"-"|"*"|"/" printf( "OPERATOR: %s\n", yytext ); "{+d}" yy_flex_debug=1; /* debug ON */ "{-d}" yy_flex_debug=0; /* debug OFF */ "{"[^}\n]*"}" /* elimina comentariile */ [ \t\n]+ /* elimina spatiile albe */
%%
void main(int argc, char **argv ){
++argv, --argc; /* se trece peste numele programului */ if ( argc > 0 )
|
Fisierul sspas.lxi poate fi accesat aici.
Desfasurarea lucrarii
Se va intocmi o specificatie FLEX continand expresii regulate dintre cele propuse in Anexa A, sau date de conducatorul lucrarii.
Se va utiliza apoi programul FLEX pentru obtinerea unui analizor lexical. Testarea analizorului se va realiza la fel ca si pentru analizorul descris in lucrarea "Proiectarea analizoarelor lexicale".
![]()
![]()