Rolul analizei lexicale
Analizorul lexical reprezinta interfata dintre programul
sursa si compilator. El realizeaza parcurgerea textului de intrare, caracter
cu caracter, grupand aceste caractere în unitati logice numite atomi.
Clasele de atomi intalnite in majoritatea limbajelor
de programare sunt: identificatori, cuvinte cheie, constante numerice (intregi,
reale, eventual reprezentate în diferite baze de numeratie), operatori
(aritmetici, logici, relationali), semne de punctuatie, delimitatori, constante
de tip caracter, respectiv sir de caractere, comentarii.
Pentru exemplificare, consideram urmatoarea secventa C:
do {
Atomii din aceasta secventa sunt:tiparire("suma=%d\n",s += f( i++ ));}while (i<10);
| do | -cuvant cheie | |
| { | -semn de punctuatie | |
| tiparire | -identificator | |
| ( | -operator | |
| "suma=%d\n" | -constanta sir de caractere | |
| , | -semn de punctuatie | |
| s | -identificator | |
| += | -operator | |
| f | -identificator | |
| ( | -operator | |
| i | -identificator | |
| ++ | -operator | |
| ) si ) | -operatori | |
| ; si } | -semne de punctuatie | |
| while | -cuvant cheie | |
| ( | -semn de punctuatie | |
| i | -identificator | |
| > | -operator | |
| 10 | -constanta numerica intreaga | |
| ) si ; | -semne de punctuatie |
Pentru fiecare atom întalnit, analizorul lexical va furniza un dublet de forma <CodLexical, atribut>. Codul lexical serveste la identificarea clasei de care apartine atomul, iar atributul (sau valoarea) identifica atomul in cadrul clasei.
Codurile lexicale sunt de regula de tip numeric. Se obisnuieste ca atomilor ce apartin claselor de dimensiuni finite (de exemplu: cuvintele cheie, semnele de punctuatie, anumiti operatori) sa li se ataseze cate un cod lexical distinct, ceea ce face ca atributul sa nu mai fie necesar. Exceptie de la aceasta regula fac unii operatori aritmetici si cei relationali, care se recomanda a fi grupati, astfel incat utilizarea lor in fazele ulterioare ale compilarii sa fie mai eficienta; si anume: fiecare grup va contine operatori avand aceeasi prioritate (de exemplu: operatorii '+' si '-' vor constitui clasa operatorilor aditivi); utilitatea acestei grupari se va vedea la proiectarea analizoarelor sintactice.
In cazul identificatorilor sau al constantelor, unde putem considera ca avem de a face cu clase de dimensiuni infinite, atributul este obligatoriu. De obicei atributul consta dintr-un indice sau pointer ce indica locul unde s-a memorat valoarea propriu-zisa a constantei respective, sau caracterele componente ale identificatorului.
Modul in care se aleg si se ataseaza codurile lexicale este la latitudinea proiectantului.
Pe parcursul analizei lexicale, în functie de limbajul
sursa , anumite grupuri de caractere sau atomi, cum ar fi: spatiile albe,
marcajele de sfarsit de linie si comentariile se neglijeaza, deoarece ele
nu au semnificatie pentru fazele urmatoare.
Structura analizorului lexical
Analizorul lexical se construieste sub forma unei proceduri care, la fiecare apel, va prelucra un nou atom; prin prelucrare se va intelege delimitarea atomului si completarea dubletului <CodLexical, atribut> corespunzator.
In vederea delimitarii atomilor, analizorul lexical trebuie sa cunoasca regulile dupa care acestia se formeaza, reguli care sunt precizate la definirea limbajului sursa. Se poate spune ca analizorul lexical este de fapt o procedura de recunoastere care, pe baza regulilor mentionate anterior, decide daca un atom apartine sau nu limbajului sursa.
In ceea ce priveste generarea perechii <CodLexical,atribut>, mai ales în cazul claselor de atomi infinite, aceasta presupune executarea anumitor actiuni de catre analizor, actiuni care sunt specifice pentru fiecare tip de atom. Pe langa acestea, in majoritatea cazurilor, analizorul lexical este cel care efectueaza gestiunea liniilor sursa (numerotare, eventual tiparire). Rutinele care implementeaza asemenea actiuni, impreuna cu rutinele de tratare a erorilor constituie rutinele semantice. Ele vor fi apelate de procedura de recunoastere, in momentul acceptarii (recunoasterii) atomilor.
Rutinele de tratare a erorilor sunt apelate atunci cand
analizorul intalneste in textul sursa secvente de caractere care nu pot
fi incadrate in nici una dintre regulile prevazute pentru atomi.
Metode de proiectare a unui analizor lexical
Pentru exprimarea regulilor de formare a atomilor, in practica se utilizeaza expresiile regulate. Pe acestea se bazeaza metodele de proiectare a analizoarelor lexicale prezentate in continuare.
In principiu exista doua asemenea metode:
![]() Metoda
manuala
Metoda
manuala
In acest caz expresiile regulate sunt transpuse in secvente de cod care, impreuna cu rutinele semantice, vor alcatui procedura de analiza lexicala. Metoda manuala este relativ simplu de implementat (de multe ori se poate baza chiar pe o descriere in limbaj natural a regulilor de formare a atomilor), dar analizorul obtinut este puternic dependent de limbajul sursa (daca se schimba expresiile regulate, analizorul trebuie rescris aproape in intregime).
![]() Metoda
automatului finit
Metoda
automatului finit
Multimea expresiilor regulate care descriu atomii limbajului sursa se transforma intr-o diagrama de tranzitie care constituie reprezentarea grafica a unui automat finit determinist de recunoastere. Proiectarea analizorului lexical in acest caz se reduce la scrierea unei proceduri care sa simuleze trecerea automatului dintr-o stare in alta, pe masura ce se parcurge textul de intrare, pana cand se ajunge intr-o stare finala (de recunoastere). Trecerile prin diferite stari vor fi insotite, dupa caz, de executia unor rutine semantice corespunzatoare.
Simularea diagramei de tranzitie se poate realiza in doua moduri:
Metoda automatului finit este mai complexa, dar algoritmul de analiza ramane practic nemodificat daca se trece la alt set de expresii regulate (se schimba doar diagrama de tranzitii). Mai mult, aceasta metoda permite realizarea generatoarelor automate de analizoare lexicale.Prin cod: tranzitiile intre stari se transcriu sub forma de cod; de obicei se utilizeaza o instructiune de selectie (de tip "case" sau "switch") care, in functie de starea curenta si de caracterul curent de intrare, determina starea urmatoare si apeleaza rutina semantica atasata.
In continuare vor fi dati algoritmii de analiza lexicala
(descrisi in pseudocod) corespunzatori metodelor de proiectare prezentate
mai sus.
Algoritmi de analiza lexicala
Se vor folosi urmatoarele notatii:
Obs: o intrare
a tabelei TabCONST va putea contine, in functie de limbajul
sursa, valori de tip intreg, real, caracter etc. De aceea, elementele acestei
tabele se vor implementa ca articole cu variante (sau structuri gen union),
de forma:
| TipCONST |
| ValCONST |
unde campul TipCONST este discriminantul. Accesarea informatiilor din tabela TabCONST va fi asigurata prin intermediul unei functii InsertConst care:
![]() Algoritmul
de analiza lexicala manuala
Algoritmul
de analiza lexicala manuala
procedure ALEX_Manual isActiunea de clasificare a caracterelor se poate detalia astfel:
*parcurgere text sursa pana la intalnirea unui caracter diferit de spatiu alb;
*clasificare caracter si prelucrare atom;
end ALEX_Manual
if ch este litera thenSe observa ca prin clasificarea caracterului ch, de fapt se stabileste atomul sau clasa de atomi care incep cu caracterul respectiv. In continuare, in cadrul prelucrarii atomului, are loc delimitarea acestuia, adica parcurgerea textului sursa pana la intalnirea primului caracter care nu mai poate sa apartina atomului respectiv. Apoi se realizeaza completarea perechii <CodLexical, atribut>.
*prelucreaza identificator sau cuvant cheie;
elseif ch este cifra then
*prelucreaza constanta numerica;
else
select ch of
'+' : *prelucreaza operator +
'-' : *prelucreaza operator -
'<' : *prelucreaza operator '<' sau '<=' sau '<>'
. . .
endselect
endif
endif
Obs: prin val(ch) s-a notat valoarea in reprezentare interna intreaga a cifrei ch. In cazul utilizarii sistemului ASCII pentru reprezentarea caracterelor, aceasta valoare este data de diferentaPrelucrarea identificatorilor
while ch este litera sau cifra do
*adauga ch in CarAtom
call GetCarUrm
endwhile
*cauta CarAtom in tabela TabCHEIE
if s-a gasit then
atom.CodLexical = codCuvCheie
*atributul se poate completa cu indicele in TabCHEIE unde s-a gasit cuvantul sau, se poate adopta
varianta in care fiecare cuvant cheie are un cod lexical distinct
else
atom.CodLexical = codIdentificator
atom.atribut = CarAtom
endif
NumInt = 0;
while ch este cifra do
NumInt = NumInt * 10 + val(ch)
call GetCarUrm
endwhile
atom.CodLexical = codConstanta
atom.atribut = InsertConst ('intreg', NumInt)
Se observa ca in cazul atomilor care nu se transmit mai departe, nu se completeaza perechea <CodLexical, atribut>, ci se apeleaza procedura de analiza pentru detectarea urmatorului atom semnificativ. Notatia EOF s-a folosit pentru a desemna marcajul de sfarsit al textului sursa.
select ch of
. . .
'<': call GetCarUrm
atom.CodLexical = codOpRel
ifch este '=' then
atom.atribut = opMaiMicEgal
call GetCarUrm
elseif ch este '>' then
atom.atribut = opDiferit
call GetCarUrm
else atom.atribut = opMaiMic
endif
endif
end '<'
. . .
endselect
Presupunand ca delimitatorii pentru comentarii sunt '{' si '}', atunci secventa de prelucrare este:
select ch of
. . .
'{': while( ch nu este '}' ) and ( ch nu este EOF) do
call GetCarUrm
endwhile
if ch este '}' then
call GetCarUrm
call ALEX_Manual
else
*trateaza eroare "sfarsit neasteptat" (comentariul nu a fost inchis);
endif
end'{'
. . .
endselect
![]() Algoritmul
de analiza lexicala automata, varianta prin cod
Algoritmul
de analiza lexicala automata, varianta prin cod
procedure ALEX_AutomatCod isunde actiune_i se poate detalia astfel:
repeat
select stare of
0: *actiune_0
1: *actiune_1
. . .
n: *actiune_n
endselect
until stare este o stare finala
end ALEX_AutomatCod
In cazul in care valoarea variabilei stare corespunde unei stari finale, actiunea respectiva consta de fapt in completarea perechii <CodLexical, atribut>.*clasificare ch
*apel rutine semantice inscrise pe diagrama
stare = *urmatoarea stare din diagrama
Pentru exemplificare vom considera o portiune dintr-o diagrama, corespunzand sablonului pentru identificatori:
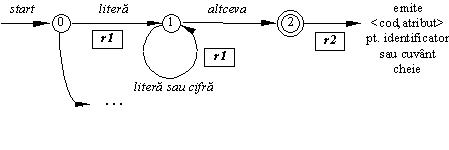
Diagrama de tranzitie pentru identificatori
Prin r1 si r2 s-au notat rutinele
semantice care se executa la tranzitiile respective.
Secventa de cod corespunzatoare diagramei de mai sus
este:
select stare ofiar rutinele semantice sunt urmatoarele:
0: if ch este litera then
callrutina_r1
callGetCarUrm
stare= 1
else
*testeaza ch pentru alte valori posibile
endif
end 0
1: if ch este litera sau cifra then
call rutina_r1
call GetCarUrm
else stare = 2
endif
end 1
2: call rutina_r2
*emite <CodLexical,atribut>
end 2
. . .
endselect
procedure rutina_r1 is
*adauga ch in CarAtom
end rutina_r1procedure rutina_r2 is
*verifica daca sirul din CarAtom se afla in TabCHEIE
if gasit then
atom.CodLexical = codCuvCheie
else
atom.CodLexical = codIdentificator
atom.atribut = CarAtom
endif
end rutina_r2
![]() Algoritmul
de analiza lexicala automata, varianta prin structuri de date
Algoritmul
de analiza lexicala automata, varianta prin structuri de date
Daca notam cu TabALEX tabloul care implementeaza diagrama de tranzitii, si daca presupunem ca o intrare din acest tablou este de forma:
| StareUrm |
| RutinaSem |
procedure ALEX_AutomatDate isObs: variabila ch1 este necesara deoarece, in cursul executiei rutinei semantice este posibil sa se modifice valoarea lui ch (prin apelul la GetCarUrm).
repeat
ch1 = ch
call TabALEX[ ch1, stare].RutinaSem
stare = TabALEX [ ch1, stare].StareUrm
until stare este o stare finala
*emite <CodLexical,atribut>
end ALEX_AutomatDate
Indiferent de metoda utilizata, procedura de analiza lexicala
respecta anumite principii de functionare. Unul dintre ele este acela ca,
intotdeauna, la intrarea in procedura variabila
ch va contine
caracterul imediat urmator atomului prelucrat anterior. De aceea, inainte
de primul apel al analizorului, trebuie sa se execute rutina GetCarUrm
(care va pozitiona ch pe primul caracter al textului sursa).
In cazul utilizarii metodei automatului finit, se va face si o initializare
a variabilei stare cu 0 (starea de start).
Tratarea erorilor lexicale
Acesta actiune presupune, pe de o parte semnalarea erorii, prin emiterea unui mesaj corespunzator, si pe de alta parte, inaintarea in textul sursa (deci neglijarea unei portiuni din el) pana la intalnirea unui caracter care sa poata fi considerat inceputul unui atom corect, de unde analiza sa poata continua normal.
In principiu, la detectarea unui atom incorect, analizorul lexical nu va returna cod de eroare, pentru a nu propaga spre analizorul sintactic erorile lexicale (fapt care ar putea genera mesaje în cascada), ci se va multumi sa emita un mesaj adecvat si, eventual, sa pozitioneze un fanion de eroare (care va servi la inhibarea fazelor ulterioare ale compilarii).
De exemplu, la intalnirea unui caracter ilegal (ce nu
apartine alfabetului limbajului sursa) se va emite mesaj, dar caracterul
respectiv va fi neglijat, incercandu-se delimitarea unui atom corect in
continuare. Sau, la intalnirea unui numar real care nu respecta restrictiile
limbajului sursa, analizorul lexical va returna cod de constanta numerica
reala, dar, prin faptul ca a emis mesaj si a pozitionat fanionul de eroare,
se va sti ca, de fapt, in text a existat o greseala.
Desfasurarea lucrarii
Se va scrie cate o procedura de analiza lexicala pentru fiecare dintre metodele prezentate, considerandu-se expresiile regulate date in Anexa A (care pot fi inlocuite sau imbogatite cu alte expresii propuse de conducatorul laboratorului).
In vederea testarii procedurilor, programul care le va apela va fi de forma:
MainProgram isValoarea gata a codului lexical va fi o valoare speciala, pe care analizorul o va atribui in cazul detectarii sfârsitului textului sursa. Drept marcaj de sfarsit se poate alege un caracter deosebit de cele ale alfabetului limbajului sursa, sau chiar caracterul EOF. Acest marcaj va fi tratat ca un atom distinct.
*sectiune de initializari
callGetCarUrm
repeat
call ALEX
*tiparire informatii despre atomul detectat
until atom.CodLexical = gata
end MainProgram
![]()
![]()