Generarea automata a analizoarelor lexicale
Principiul generarii automate a analizoarelor lexicale
Un generator de analizoare lexicale porneste de la setul
de expresii regulate care descriu toti atomii limbajului sursa si, pe baza
unor algoritmi ce vor fi prezentati mai jos, obtine diagrama de tranzitie
corespunzatoare, sub forma unei tabele de analiza, avand structura similara
celei indicate in Lucrarea "Proiectarea analizoarelor
lexicale" (paragraful Algoritmul de
analiza lexicala automata, varianta prin structuri de date). Aceasta
tabela, impreuna cu procedura de analiza (prezentata in acelasi paragraf),
alcatuiesc analizorul lexical.
Obtinerea tabelei de analiza pe baza expresiilor regulate
In literatura de specialitate se prezinta doua modalitati de transformare a expresiilor regulate in automate finite deterministe.
![]() 1.Metoda
Thompson
1.Metoda
Thompson
Aceasta metoda presupune parcurgerea a trei etape:
Dandu-se o expresie regulata ER, se doreste obtinerea automatului finit nedeterminist (AFN) care sa accepte limbajul descris de ER.Construirea unui automat finit nedeterminist (AFN) pornind de la expresiile regulate (ER).
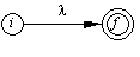
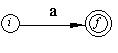
Obs: pentru fiecare AFN elementar construit, starile vor fi notate cu nume (numere) distincte; daca un acelasi simbol al alfabetului apare de mai multe ori in ER, se va construi pentru fiecare aparitie a sa cate un AFN separat, cu stari notate distinct. In schemele de mai sus, cu i si f s-au notat starea de start, respectiv starea finala a AFN.a) pentru lambda (simbolul vid):
In cele ce urmeaza vom nota cu Ni
AFN corespunzator ER Ri.
Regulile de compunere sunt:
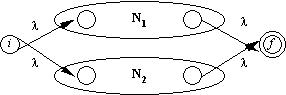
c) pentru R1|R2
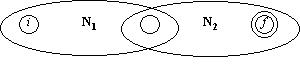
e) pentru R1*
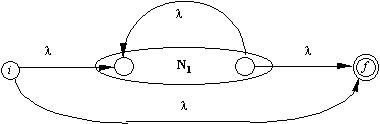
AFN final va avea o singura stare de start si o singura stare finala.
Pe baza AFN obtinut aplicand regulile de mai sus, se va construi un automat finit determinist (AFD) care sa accepte acelasi limbaj ca si AFN.1.2.Transformarea AFN in AFD
procedure AFN2AFD isFunctia lambda-inchidere este definita pe o multime T de stari ale AFN si reprezinta multimea starilor in care se poate ajunge pornind de la starile din T, pentru simbolul lambda.
*initializeaza Dstari cu lambda-inchidere({s0})
*la inceput starile din Dstari sunt nemarcate
Dtranz= multimea vida
while mai exista in Dstari o stare x = {s1, s2, . . . ,sn} nemarcata do
*marcheaza x
for fiecare a din Sigma do
*fie T = multimea starilor din AFN pentru care exista o tranzitie etichetata cu a de la o
stare si din x;
y = lambda-inchidere(T);
ify nu se afla in Dstarithen
*adauga y ca stare nemarcata la Dstari
*adauga tranzitia xy la Dtranz, daca nu exista deja
endif
endfor
endwhile
end AFN2AFD
function lambda-inchidere( T ) isStarile acceptoare ale AFD obtinut vor fi acele stari x care vor contine cel putin o stare acceptoare a AFN. Starea de start a AFD este cea formata din s0 impreuna cu toate starile la care se poate ajunge din s0 doar prin simbolul lambda.
*pune toate starile din T intr-o stiva
*initializeaza lambda-inchidere( T ) cu T
while stiva nu e vida do
*extrage starea s din varful stivei
for fiecare stare t pentru care exista st do
if t nu se afla in lambda-inchidere( T ) then
*adauga t la lambda-inchidere( T )
*pune t in stiva
endif
endfor
endwhile
end lambda-inchidere
De cele mai multe ori AFD obtinut cu algoritmul de mai sus nu este cel mai mic posibil (cu numar minim de stari). Reducerea numarului de stari ale AFD implica urmatorii pasi:
Se realizeaza o partitionare P a multimii Dstari care, initial, consta din doua grupuri de stari:
Printr-o procedura, care se va da mai jos, se incearca efectuarea unei noi partitionari, Pnou, prin descompunerea grupurilor lui P in subgrupuri. Daca Pnou este diferit de P, se inlocuieste P cu Pnou si se repeta procedura de descompunere. DacaPnou este identic cu P, inseamna ca partitionarea nu se mai poate face.
- F = setul de stari acceptoare si
- Dstari - F = setul de stari non-acceptoare.
![]() Din
fiecare grup al partitiei obtinute in pasul anterior, se alege cate o stare
oarecare (stare reprezentanta). Acestea vor fi starile AFD minimizat. Starea
initiala va fi starea reprezentanta a grupului ce contine starea initiala
s0,
iar starile finale vor fi reprezentantele subgrupurilor provenite din F.
Din
fiecare grup al partitiei obtinute in pasul anterior, se alege cate o stare
oarecare (stare reprezentanta). Acestea vor fi starile AFD minimizat. Starea
initiala va fi starea reprezentanta a grupului ce contine starea initiala
s0,
iar starile finale vor fi reprezentantele subgrupurilor provenite din F.
![]() Daca
AFD minimizat contine o stare de blocaj d,
adica o stare care nu este finala si care tranziteaza in ea insasi pentru
toate simbolurile
a din Sigma, aceasta stare
se elimina. Se vor elimina, de asemenea, starile care nu pot fi atinse
plecand din starea initiala. Tranzitiile spre starile de blocaj dinspre
alte stari devin nedefinite.
Daca
AFD minimizat contine o stare de blocaj d,
adica o stare care nu este finala si care tranziteaza in ea insasi pentru
toate simbolurile
a din Sigma, aceasta stare
se elimina. Se vor elimina, de asemenea, starile care nu pot fi atinse
plecand din starea initiala. Tranzitiile spre starile de blocaj dinspre
alte stari devin nedefinite.
![]() 2.Metoda
arborelui binar
2.Metoda
arborelui binar
Aceasta metoda presupune:
Arborele corespunzator ER va avea cate un nod terminal pentru fiecare simbol ce apare in ER si cate un nod interior pentru fiecare operator aplicat (concatenare, inchidere,selectie). In prealabil ER va fi modificata, in sensul ca la sfarsitul ei va fi concatenat un simbol special, notat cu #, care va servi drept marcator de sfarsit al ER. O asemenea ER modificata se numeste ER augmentata.
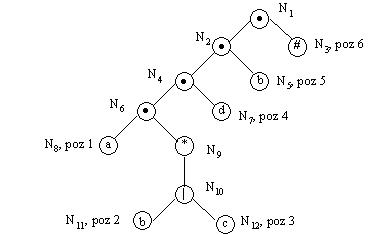
In AFD corespunzator ER augmentate, orice stare de la care va exista o tranzitie etichetata cu '#' va fi stare acceptoare.Luand ca exemplu ER augmentata :
arborele corespunzator va fi cel din figura de mai jos.
Fiecare simbol din ER va fi numerotat, in ordinea textuala
a aparitiei sale in ER. Daca acelasi simbol apare de mai multe ori, fiecare
aparitie va avea un numar distinct. Numerele atribuite in acest mod se
numesc pozitii. Pe de alta parte, fiecare
nod al arborelui va primi cate un identificator unic, pentru a putea fi
localizat. In cazul arborelui din figura de mai sus identificatorii nodurilor
au fost notati cu Ni, i = 1. .12.
Obs: daca
ER pentru care se construieste arborele este de forma a | b, atunci forma
augmentata va fi (a |b) #, deoarece operatorul de concatenare are precedenta
mai mare fata de operatorul selectie.
Ca si in cazul algoritmului
lui Thompson, arborele se obtine aducand ER la forma postfix.
Notand cu rad nodul radacina al arborelui si preluand notatiile Dtranz si Dstari de la paragraful anterior, algoritmul de transformare a arborelui ER in AFD este:
procedure ER2AFD isFunctia Pozurm(i), unde i este o pozitie din arborele ER, returneaza multimea pozitiilor j care pot urma pozitiei i in arbore. Calculul acestei multimi presupune ca, in prealabil, pentru fiecare nod n din arbore, sa se determine doua multimi: Primapoz(n) si Ultimapoz(n). Se face observatia ca n este identificatorul nodului, NU pozitia.
*initializeaza Dstari cu Primapoz(rad)
*la inceput starile din Dstari sunt nemarcate
while exista stare nemarcata T in Dstari do
*marcheaza T
for fiecare a din Sigma do
U = multimea vida
for fiecare p din T do
if a este simbolul din pozitia p then
U = U + Pozurm(p) // '+' inseamna reuniune
endif
endfor
if (U nu este multimea vida) and ( U nu se afla in Dstari ) then
*adauga U ca stare nemarcata la Dstari
endif
*adauga tranzitia T
endfor
endwhile
end ER2AFD
O stare a AFD din Dstari va fi o multime formata din numere de pozitii din arbore. Fiecare asemenea multime va primi cate un identificator de stare distinct. De obicei identificatorii de stari sunt numere intregi. Se observa ca operatia din linia notata cu (**) se executa chiar daca U este multimea vida. Acest lucru se intampla cand simbolul a de pe pozitia p este chiar terminatorul '#'. Semnificatia unei asemenea tranzitii este aceea ca starea reprezentata de T este stare acceptoare.
Functia Primapoz(n) defineste multimea pozitiilor corespunzatoare cu primul simbol al unui sir generat de subarborele cu radacina in n.
Analog, Ultimapoz(n) defineste multimea pozitiilor corespunzatoare cu ultimul simbol dintr-un sir generat de subarborele cu radacina in n.
Pentru calculul acestor functii este necesar sa se determine acele noduri care sunt radacini ale unor subarbori ce pot genera sirul vid. Asemenea noduri se numesc anulabile. Vom defini, in consecinta, o functie Anulabil(n) care va returna valoarea logica true daca n este un nod anulabil, si false in caz contrar.
Regulile de calcul pentru functiile
Anulabil
si
Primapoz
sunt
date in tabelul de mai jos.
|
|
|
|
| Frunza cu eticheta lambda |
|
|
| Frunza avand pozitia i |
|
|
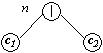 |
or Anulabil(c2) |
Primapoz(c1) + Primapoz(c2) |
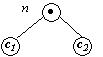 |
|
if Anulabil(c1)
then
Primapoz(c1) + Primapoz(c2) else Primapoz(c1) endif |
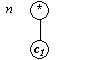 |
|
Primapoz (c1) |
Obs: operatorul '+' semnifica reuniune de multimi.
Pentru Ultimapoz regulile sunt similare cu cele de la Primapoz, doar ca se inlocuieste Primapoz cu Ultimapoz si se interschimba c1 cu c2 .
Acum, regulile pentru calculul lui Pozurm(i) sunt:
procedure Calc_Pozurm is
for fiecare pozitie p din arbore do
*initializeaza Pozurm(p) cu multimea vida
endfor
for fiecare nod n din arbore do
ifn este un nod concatenare then
*fie c1 si c2 fiii stang, respectiv drept ai lui n
for fiecare pozitie i din Ultimapoz(c1) do
*adauga Primapoz(c2) la Pozurm(i).
endfor
endif
ifn este un nod inchidere then
for fiecare pozitie i din Ultimapoz(n) do
*adauga Primapoz(n) la Pozurm(i).
endfor
endif
endfor
end Calc_Pozurn
Pentru exemplificare, in tabelul de mai jos se dau
valorile calculate ale functiilor Anulabil,
Primapoz,
Ultimapoz
si Pozurm corespunzatoare arborelui
dat la inceputul paragrafului.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
In concluzie, etapele care se parcurg pentru obtinerea AFD pe baza arborelui unei ER sunt:
Atasarea actiunilor semantice
Pentru simplificare, algoritmul de analiza va fi proiectat astfel incat, in timpul delimitarii unui atom sa se memoreze caracterele componente ale atomului intr-un buffer separat (de exemplu CarAtom folosit in lucrarea "Proiectarea analizoarelor lexicale"). In momentul cand se ajunge in starea acceptoare corespunzatoare atomului respectiv, se vor efectua operatiile dorite, utilizandu-se bufferul. Cu alte cuvinte, vom avea rutine semantice atasate doar cu starile acceptoare.
Desfasurarea lucrarii
Se va proiecta cate un generator de tabele de analiza
lexicala, utilizand metodele descrise in lucrare. Generatoarele vor primi
la intrare lista expresiilor regulate pe baza carora vor construi AFN,
respectiv arborele ER, apoi vor intocmi tabelele de analiza. Prelucrarea
expresiilor regulate de la intrare se va face utilizand gramatica propusa
in Anexa E.
La generatoarele obtinute se va atasa procedura de analiza
lexicala automata, varianta prin structuri de date descrisa in lucrarea
"Proiectarea analizoarelor lexicale", si se va
analiza un text de intrare continand atomi formati dupa ER avute in vedere.
ER se vor lua fie din Anexa A,
fie vor fi propuse de conducatorul lucrarii.
![]()
![]()