Lucrarea nr. 4
Reinforcement Learning
Procesul de invatare, in general, este un proces
in urma caruia agentul in cauza (cel care invata) isi imbunatateste capacitatea
de actiune astfel incat, in timpul unor solicitari ulterioare, agentul
intreprinde actiuni cu eficienta crescuta. Actiunile agentului au loc in
cadrul unui mediu, iar in functie de interactiunea dintre agent si mediu
se disting urmatoarele tipuri de invatare:
-
Supervised learning (invatarea supervizata
): mediul inconjurator ofera atat problemele pe care le are
de rezolvat agentul, cat si raspunsurile corecte la aceste probleme
-
Reinforcement learning:
mediul inconjurator furnizeaza date despre corectitudinea acitunilor intreprinse
de agent, dar nu spune care sunt actiunile corecte.
-
Unsupervised learning (invatarea
nesupervizata): mediul inconjurator nu ofera informatii despre
corectitudinea actiunilor intreprinse de agent.
Agentul care se bazeaza pe reinforcement learning
invata
ce sa faca (ce actiuni sa efectueze in anumite situatii) astfel incat sa
maximizeze un semnal numeric numit
recompensa (reward). Spre deosebire de
majoritatea formelor de invatare in care agentului i se spune dinainte
ce actiuni sa intreprinda, in cazul invatarii prin reinforcement agentul
trebuie sa descopere singur care actiuni duc la obtinerea unei recompense
mai mari. Cel mai interesant este faptul ca actiunile intreprinse pot afecta
nu numai recompensa obtinuta imediat la pasul urmator, dar si situatia
urmatoare, si in consecinta toate recompensele viitoare.
Un sistem bazat pe reinforcement learning este
format din urmatoarele elemente:
-
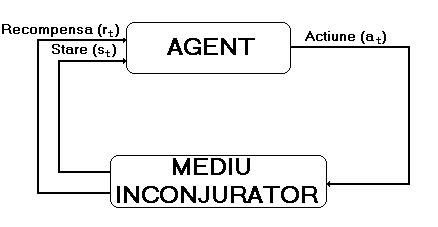
agentul care invata (totodata, agentul este
si cel care ia deciziile de efectuare a actiunilor; el interactioneaza
cu lucrurile din jurul sau, adica cu mediul inconjurator--
vezi figura de mai jos)
-
o politica care se defineste comportamentul
agentului la un moment dat (ce actiuni intreprinde acesta pus in anumite
situatii)
-
o functie de recompensa (defineste tinta care
se doreste sa fie obtinuta; aceasta functie realizeaza o asociere intre
o stare (sau perechi de stari-actiuni) si un numar ce indica dorinta de
a se ajunge in acea stare, cu alte cuvinte, cu cat recompensa primita intr-o
stare este mai mare, cu atat agentul va dori mai mult ca pe viitor sa ajunga
in starea respectiva)
-
o functie de evaluare (spre deosebire de recompensa,
care indica buna calitate a unei stari in sensul imediat, functia de evaluare
se refera la aceasta caracteristica pe o perioada de timp mai indelungata,
fiind cantitatea totala de recompense pe care agentul se asteapta sa o
obtina in viitor pornind din starea respectiva; se poate astfel ca o stare
in care recompensa primita sa fie mica sa aiba totusi o valoare ridicata
a functiei de evaluare, deoarece starea respectiva este urmata in mod obisnuit
de stari care produc recompense ridicate)
-
un model al mediului inconjurator (acesta
simuleaza comportamentul mediului inconjurator, adica pe baza unei stari
a mediului si a unei actiuni a agentului, modelul poate prezice care este
starea urmatoare precum si recompensa rezultata; modelele sunt utilizate
pentru planificare, adica pentru luarea unor decizii de actiune
prin considerarea unor posibile situatii(stari) viitoare inainte ca aceste
stari sa fie experimentate)
In general, orice problema de invatare prin interactiune
si orientata spre un anumit scop(tinta) se poate reduce la trei semnale
care se transmit intre agent si mediul inconjurator: actiunile (alegerile
facute de agent/deciziile luate de agent), starile (pe care se bazeaza
agentul in luarea deciziilor), recompensele (definesc scopul urmarit
de agent).
Pentru a exemplifica abordarea unei probleme utilizand reinforcement learning si estimarea unei functii de evaluare, vom contrui un tabel de numere, cate unul pentru fiecare stare posibila. Fiecare numar va estima probabilitatea de atingere a tintei pornind din acea stare. Intreg tabelul reprezinta functia de evaluare invatata. Pe baza acestei functii se defineste calitatea unei stari in urmatorul mod: o stare A este mai buna decat o stare B daca estimarea curenta a probabilitatii de atingere a tintei din starea A este mai mare decat cea din starea B. In general, valorile initiale din tabel se seteaza arbitrar (desi in functie de natura aplicatiei se pot utiliza si initilizari bazate pe anumite informatii specifice).
Pentru procesul de invatare, agentul va fi lasat sa execute o serie de actiuni conforme cu politica sa. Fiecare selectie a actiunii curente se va baza pe starea curenta si pe valoarea asociata din tabel. In general, actiunile se selecteaza pe baza unei strategii greedy, adica se va selecta acea actiune care ne duce in starea cu valoarea maxima a estimatorului (acest fapt face insa posibila uneori blocarea functiei de evaluare intr-un punct de maxim local, lucru care se poate contracara prin alegerea din cand in cand a unor actiuni de explorare, care se aleg in mod arbitrar dintre actiunile posibile la momentul respectiv).
Dupa fiecare actiune, agentul va ajusta valorile din tabel, astfel incat ele sa tinda spre valorile starilor sale urmatoare cele mai probabile, pe baza formulei:
V(s) <- V(s) + alfa *[V(s') - V(s)]
unde V este functia de evaluare, s reprezinta starea curenta, s' este starea urmatoare iar alfa este rata de invatare. Aceasta formula pentru ajustarea functiei de evaluare este un exemplu de invatare prin diferenta temporala (temporal difference).
Aceasta formula suporta usoare variatii in functie de metoda de abordare utilizata: programare dinamica, metode Monte-Carlo si Temporal Difference. In lucrarea de fata se va studia cazul cel mai general, TD(lambda). Pentru cazul TD(0), formula va fi:
V(s) <- V(s) + alfa *[r' + gama * V(s') - V(s)]
unde r' este recompensa primita in starea urmatoare, iar gama este rata de descrestere (aceasta face ca transmiterea informatiei de la starea tinta inspre o stare anterioara sa se degradeze pe masura ce distanta - exprimata in numar de stari - dintre cele doua stari este mai mare).
In cazul TD(lambda), se foloseste pentru ajustare nu numai valoarea starii urmatoare, ci a unei serii intregi de stari urmatoare. Se memoreaza in acest sens intr-un alt tabel niste valori numite eligibility traces, care se noteaza e(s) si se bazeaza pe urmatoarea functie:
gama * lambda * e(s), daca s <> s(t)
e'(s) =
gama * lambda * e(s) + 1, daca s == s(t)
unde e(s) este valoarea asociata starii s la momentul de timp t, e'(s) este valoarea asociata starii s la momentul de timp t+1, iar lambda este rata de degradare a valorilor din acest tabel.
In continuare se prezinta varainta online a algoritmului TD(lambda):
- Initializeaza V(s) arbitrar si e(s) = 0 pentru toate s din S
- Pentru fiecare episod, repeta:
- Initializeaza s
- Pentru fiecare pas al episodului, repeta:
- Fie a actiunea data de politica curenta pentru starea s
- Executa actiunea a, observa recompensa r si starea urmatoare s'
- delta <- r + gama * V(s') - V(s)
- e(s) <- e(s) + 1
- Pentru toate starile s:
- V(s) <- V(s) + alfa * delta * e(s)
- e(s) <- gama * lambda * e(s)
- s <- s'
- Pana cand s este stare finala
Tema: 1